for a homework assignment i have to plot the word frequencies of a text and compare it to an optimal zipf distribution.
Plotting the counted word frequencies of the text according to their rank in a log log graph seems to work fine.
But i have trubble with calculating the optimal zipf distribution. The result should look something like this:
I dont understand what the equation would look like to calculate the straight zipf line.
On the german wikipedia page of the zipf law I found an equation that seems to work

but there are no sources cited, so i dont understand where the constant of 1.78 comes from.
#tokenizes the file
tokens = word_tokenize(raw)
tokensNLTK = Text(tokens)
#calculates the FreqDist of all words - all words in lower case
freq_list = FreqDist([w.lower() for w in tokensNLTK]).most_common()
#Data for X- and Y-Axis plot
values=[]
for item in (freq_list):
value = (list(item)[1]) / len([w.lower() for w in tokensNLTK])
values.append(value)
#graph of counted frequencies gets plotted
plt.yscale('log')
plt.xscale('log')
plt.plot(np.array(list(range(1, (len(values)+1)))), np.array(values))
#graph of optimal zipf distribution is plotted
optimal_zipf = 1/(np.array(list(range(1, (len(values)+1))))* np.log(1.78*len(values)))###1.78
plt.plot(np.array(list(range(1, (len(values)+1)))), optimal_zipf)
plt.show()
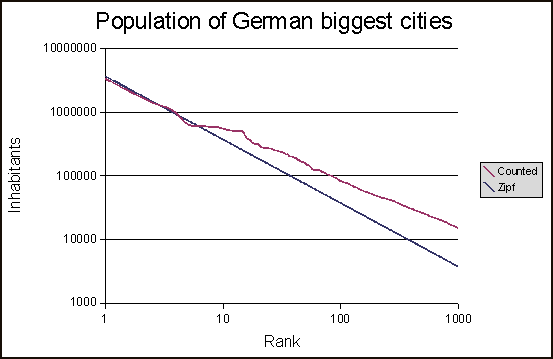
My results with this script look like this:

but i am just not sure if the optimal zipf distribution is calculated right. If so, shouldnt the optimal zipf distribution cross the X-axis at one point?
EDIT: if it helps, my text has 2440400 tokens and 27491 types

Take a look at this research paper by Andrew William Chisholm. Specifically page #22.