I am looking methods to embed variable length sequences with float values to fixed size vectors. The input formats as following:
[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]-> ... -> [f1,f2,f3,f4]
[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]->[f1,f2,f3,f4]-> ... -> [f1,f2,f3,f4]
...
[f1,f2,f3,f4]-> ... -> ->[f1,f2,f3,f4]
Each line is a variable length sequnece, with max length 60. Each unit in one sequece is a tuple of 4 float values. I have already paded zeros to fill all sequences to the same length.
The following architecture seems solve my problem if I use the output as the same as input, I need the thought vector in the center as the embedding for the sequences.
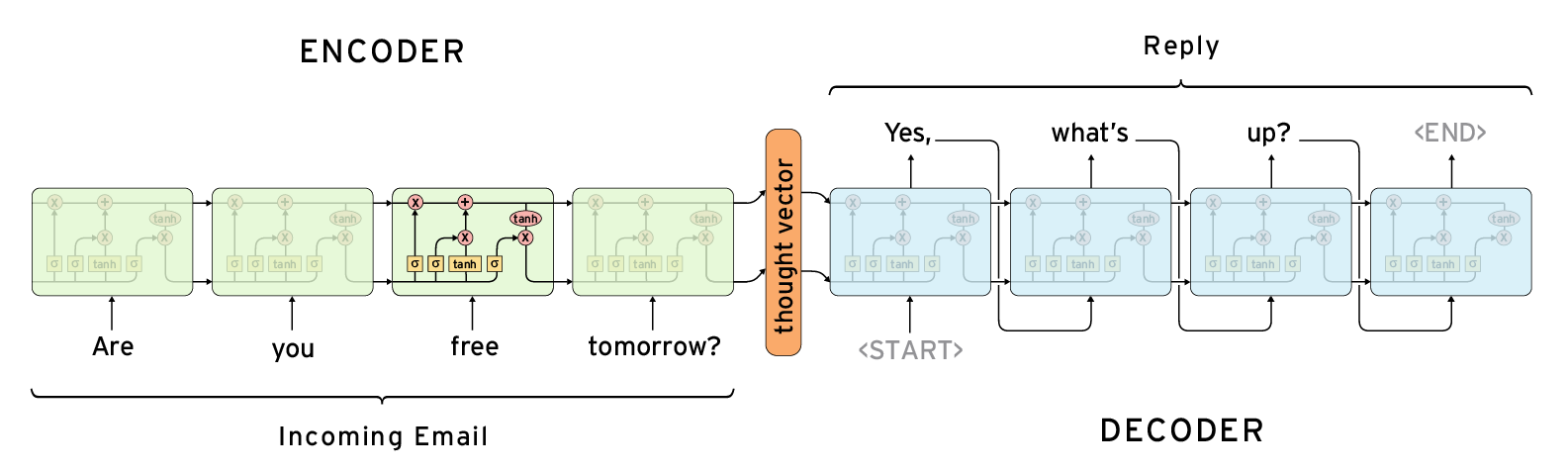
In tensorflow, I have found tow candidate methods tf.contrib.legacy_seq2seq.basic_rnn_seq2seq and tf.contrib.legacy_seq2seq.embedding_rnn_seq2seq.
However, these tow methos seems to be used to solve NLP problem, and the input must be discrete value for words.
So, is there another functions to solve my problems?

I have found a solution to my problem, using the following architecture,
The LSTMs layer below encode the series x1,x2,...,xn. The last output, the green one, is duplicated to the same count as the input for the decoding LSTM layers above. The tensorflow code is as following